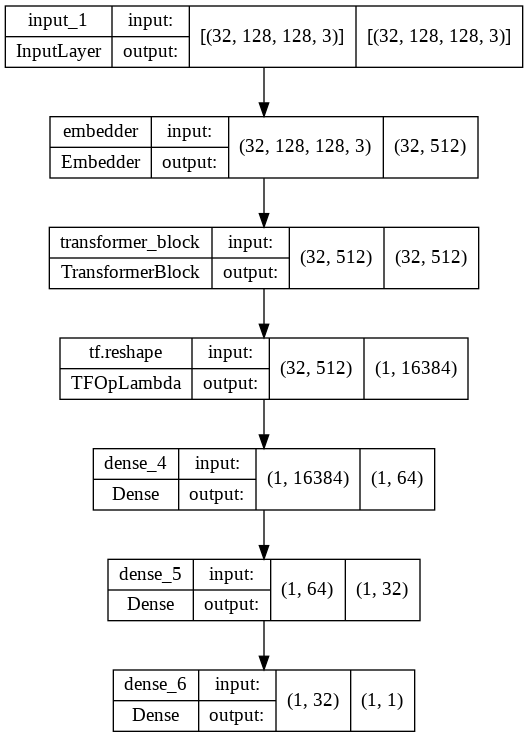
Abstract: Transformers have made impactful progress in NLP and are now transforming Computer Vision. Through this project, I tried to understand the the effects on the learning of Spatial-Temporal features if we feed the Vision Transformer frames of a video rather than 3D patches. I used a subset of the Youtube-8M dataset. I chose two classes Basketball dribbling and Basketball dunking as they depended more on the temporal features rather than the content. I was able to achieve an accuracy of 71.6% on the training dataset in just one epoch. I am yet to train it for longer durations as each epoch took significant amount of time on my local machine.